I/O子系统
本人觉得I/O子系统是Linux内核中最难的东西,因为它需要兼容横跨物理介质、文件系统、空间位置(网络),为上层提供统一接口,还需要保持高性能,这简直amazing。
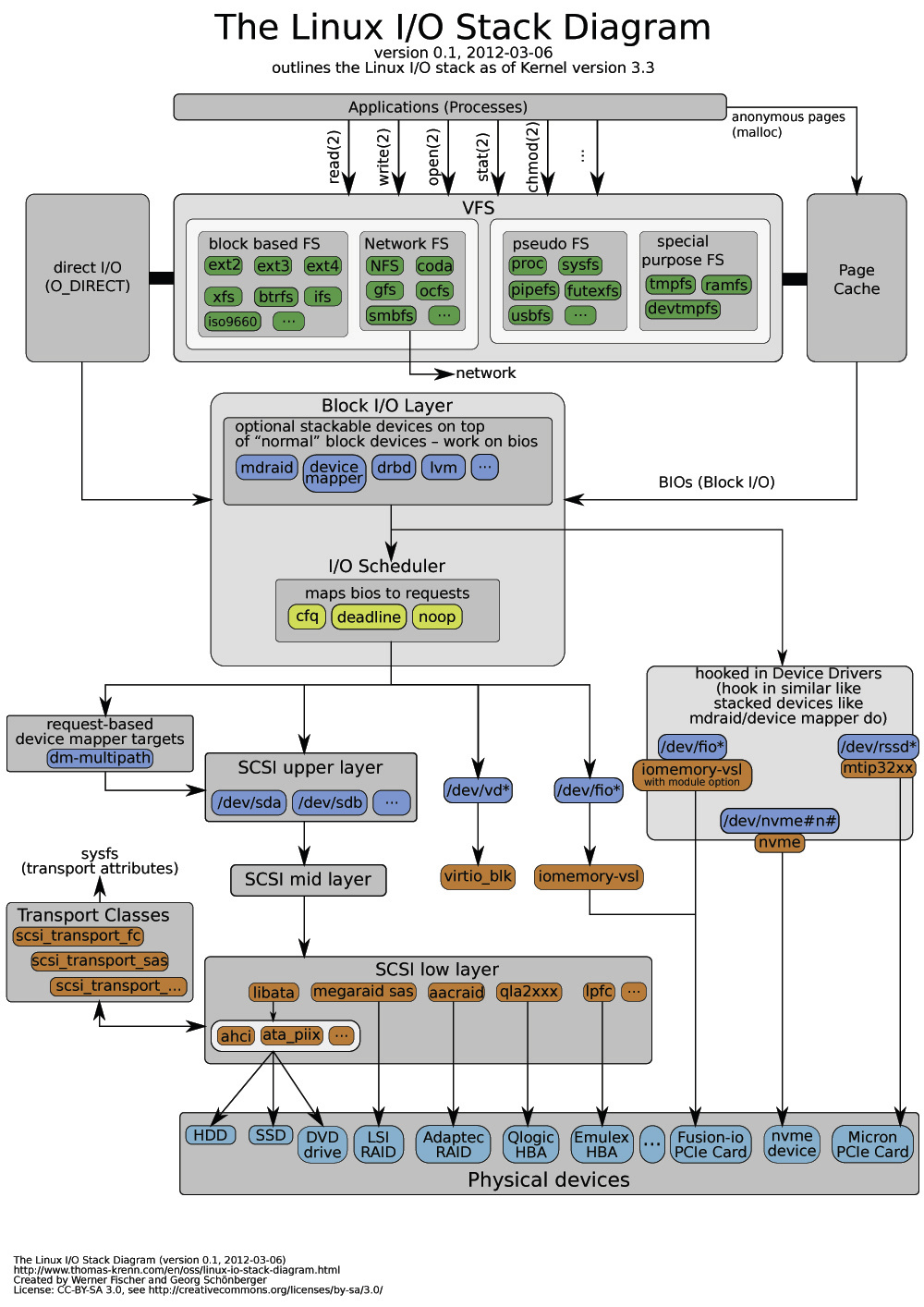
I/O子系统的架构图如上图所示。
这里将Linux I/O子系统分为VFS(虚拟文件系统)、块I/O、高速缓存这三个部分总结。
VFS
VFS作为内核子系统,为上层例如open、write等系统调用提供了统一的接口,而不需要考虑文件系统和具体物理介质。它建立了一个文件抽象层,要求不同的文件系统驱动都实现遵守这个统一的文件系统模型。
不同于Windows这种将具体的设备和分区划分命名空间(比如命名空间C:分配给固态硬盘设备的一个分区,D:分配给另一个分区,E:分配给另一个存储设备)的操作系统,Unix类的操作系统所有的文件系统都被安装在一个特定的安装点下面,也就是说安装点文件系统作为一个树的枝叶出现在系统中,相当优雅。例如一个文件:
1 | /home/lyq1996/deadbeef |
它包括:/目录,/home目录,/home/lyq1996目录,deadbeef文件。在Linux中,目录也被当作一个文件,所以可以对目录进行操作。
VFS对象
包括:
- 超级块对象:代表已安装的操作系统
- inode对象:代表一个具体文件
- dentry对象:代表一个目录项,路径组成部分
- 文件对象:代表进程打开的文件

超级块
超级块,包含了文件系统的重要信息,比如inode的总个数、块总个数、每个块组的inode个数、每个块组的块个数等信息,超级块对象在挂载文件系统时从物理设备读入内存。对于内存文件系统,例如sysfs,procfs,tmpfs等,会现场创建超级块,并保存到内存中。
超级块结构体见struct super_block,最重要的域是struct super_operations s_op,包含了操作超级块的函数。也就是说,这里采用的是面向对象的思想,数据与数据操作绑定了。
inode、dentry、file
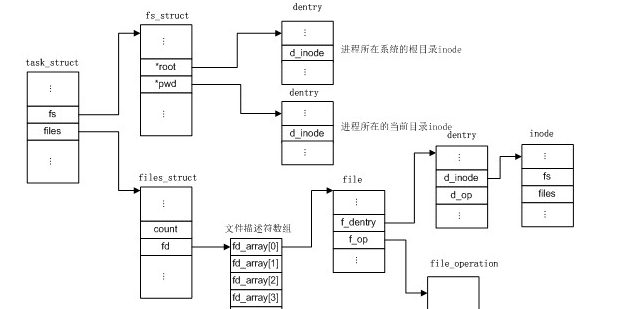
索引节点
Unix将文件和文件元数据划分开,元数据被称为inode(索引节点),inode结构体包括了访问权限控制、大小、时间等信息。索引节点也需要保存到物理设备上,对于有些没有单独保存元信息的文件系统,或者没有单独存放,文件系统也必须要提取这些信息。inode表示文件系统的一个文件,并不会将所有的inode一次性保存到内存,只有该文件被访问时才会在内存中创建,索引节点表示的文件可以是设备文件、管道文件。
索引节点见struct inode,和超级块一样,域struct inode_operations *i_op包含了操作索引节点的函数。
目录项存在三种状态:被使用,未使用,负状态。被使用的目录项,对应一个有效的索引节点,并存在一个或多个使用者,通过d_count标记;未使用的目录项,对应一个有效的索引节点,但没有使用,d_count为0;而负状态的目录项,则没有有效的索引节点,保留在内存中用作快速查询。
如果每一个文件,访问时都依次解析成目录项对象,无疑非常的费力,因此内核将目录项缓存到目录项缓存中,也就是dcache。访问一个文件时,VFS首先在目录项缓存中查找路径名,如果找到了,则直接返回目录项。目录项同时也提供了一定意义上的inode缓存,因为目录项会让相关inode索引节点的计数为正,这样inode就不会被释放,也就不需要将inode重新加载到内存。
目录项
目录项对象可以想象成一个查找文件用的目录,上面提到了一个路径/home/lyq1996/deadbeef,/是目录项对象,/home,lyq1996/,/deadbeef也是目录项对象。同样,目录项对象的操作保存在域struct dentry_operations *d_op中。
文件对象
文件对象表示进程打开的一个文件,进程处理的是文件,当然不是dentry和inode。文件对象没有对应的磁盘数据,所以状态没有脏、是否需要回写的标记,因为文件对象有一个指针指向dentry,dentry会指向对应的索引节点,索引节点中会记录文件是否为脏的。文件对象操作保存在struct file_operations *f_op中。
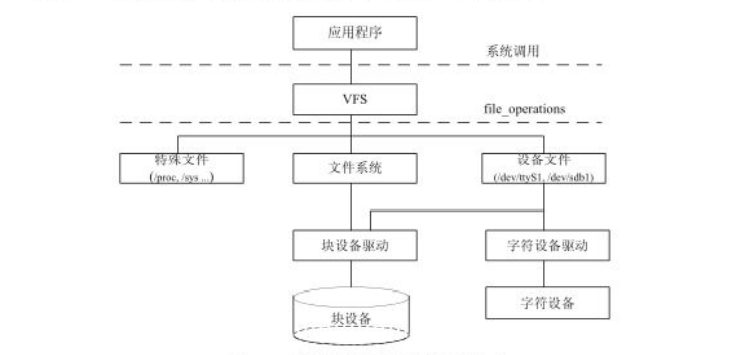
对于字符设备,还有一些特殊文件,比如/proc和/sys,它们没有文件系统,所以这些文件对象的操作直接由设备驱动提供。
进程相关数据结构
每个进程都有自己打开的文件,根文件系统、当前工作目录、安装点等。存在三个结构体与进程紧密相连,分别是:files_struct、fs_struct、namesapce结构体。
files_struct:由task_struct的files域指向,包含与单个进程相关的信息,比如打开的文件和文件描述符。
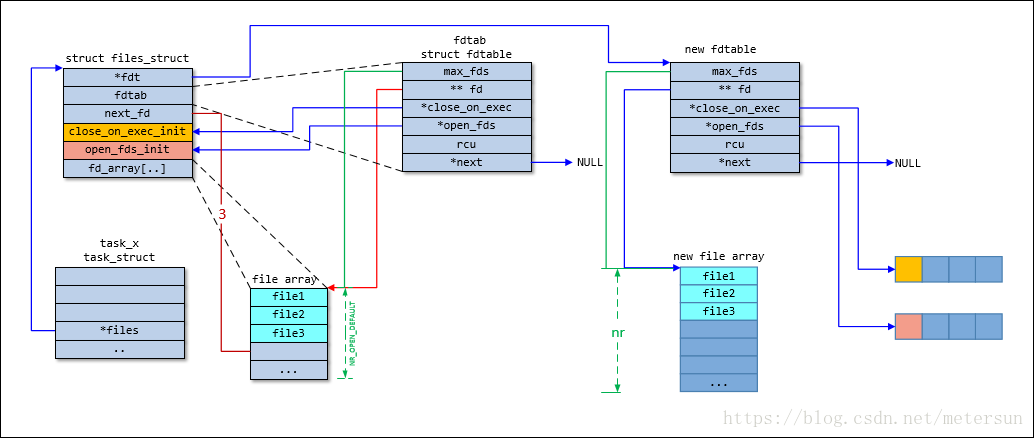
图片来自CSDN-metersun。
files_struct定义如下:
1 | struct files_struct { |
fs_struct:由task_struct的fs域指向,包含文件系统和进程相关的信息。
fs_struct定义如下:
1 | struct fs_struct { |
mnt_namespace:由task_struct的namespace结构体,由task_struct的mmt_namespace域指向。默认所有的进程共享相同的命名空间,除非在clone时使用CLONE_NEWS标志。namespcae可以隔离资源,docker就采用了这种技术,除了mmt_namespace以外,还有uts_namespace,ipc_namespace,pid_namespace等。
mnt_namespace定义入下:
1 | struct mnt_namespace { |
文件系统的挂载
只有理解了文件系统的挂载,才能真正串联这些结构体。
推荐阅读:
- 深入理解Linux文件系统之文件系统挂载(上)
- 深入理解Linux文件系统之文件系统挂载(下)
块I/O
块指的是文件系统寻址的最小单元,扇区是块设备寻址的最小单元。在以前,大多数块设备扇区可能是512字节,块大小是扇区大小的2的整数倍,且不能超过页大小,所以块大小为512B、1KB、4KB,也就是一个块包含1、2、4个扇区。
目前,用的最多的ext4文件系统的块大小通常为4KB,与页面的大小4KB一致。而且硬盘设备的容量越来越大,设备扇区寻址支持和块大小保持一致,这也就是所谓的4K对齐。
缓冲区
当一个块被调入内存时,需要存放在内存的缓冲区中,所以缓冲区就是块在内存中的表示,缓冲区头结构见struct buffer_head。
1 | struct buffer_head { |
b_this_page是页面中的缓冲区,b_page是存储缓冲区的页面,b_blocknr是起始块号,b_data是页面中的数据指针,它直接指向相应的块(位于b_page的某个位置),b_bdev指向对应的块设备。缓冲区头的目的在于描述块和内存缓冲区的关系。
在2.6内核以前,缓冲区头作为所有I/O操作单元的容器,历史上存在的东西也没必要仔细细究。目前内核中块IO操作的基本容器以bio结构体表示,结构体表示目前活动的、以片段(segment)链表形式组织的块IO操作。
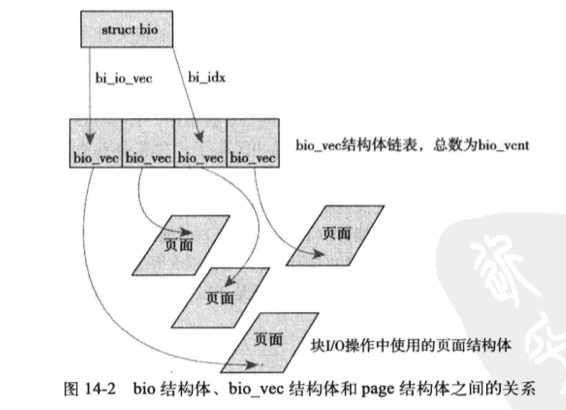
bi_io_vec域表示一个IO操作所关联的所有片段,每个bio_vec都是一个page,offset,len的向量,描述了片段所在的物理页、块在物理页的偏移位置、块的长度。整个bi_io_vec数组表示了一个完整的缓冲区。总而言之,每个IO请求都是通过bio结构体表示的,每个请求包含一个或多个块。
bio与之前缓冲区不同之处在于,bio代表的是抽象的IO操作,作为一个或者多个IO块的容器,包含了一个或者多个页中的片段,而缓冲区描述的仅仅是一个块,所以可能会引起以块为单位的分割,需要后续的处理重新组合。
- bio结构体可以处理高端内存,物理页不是直接指针。
- bio可以代表普通IO,也可以代表直接IO,不通过页高速缓存
- bio便于执行分散-集中的块IO操作
- bio结构体只需要包含块IO操作所需的信息即可,不需要包含与缓冲区本身不必要的信息。
IO调度
IO调度程序负责对IO请求队列中的请求进行调度,有利于减少寻址时间,提高吞吐量。这部分等以后工作中真正遇到了在进行详细的学习(日后如果有机会进行性能调优的话…)。
IO调度有:
- Linus电梯
- deadline
- CFQ
- Noop
….
页高速缓存
前言:
我在学习这部分内容的时候产生了相当大的疑惑,页高速缓存是将磁盘中的数据缓存到物理内存中,相当于对磁盘的访问变成了对物理内存的访问。而上面介绍了bio结构体,是块IO在内存中的表示,它映射了内存中的页面到磁盘块,这样页高速缓存在进行块IO操作时也减少了磁盘访问。那么,在对某一个磁盘块进行操作时,通过块IO缓冲会保存在内存中一份,通过页面高速缓存也会保存在内存中一份,两份内存??还得保持两个缓存的同步??
其实,这两个并非天生统一,2.4内核主要工作将是统一它们。因此在实现上,块IO缓冲区没有作为独立缓存,而是作为了页高速缓存的一部分。但是内核仍然需要在内存中使用IO缓冲来表示块,而缓冲是用页映射块(还记得吗?),所以它正好在页高速缓存中。
读缓存
页高速缓存由内存中的物理页组成,页对应物理块。当内核开始一个读操作时,首先检查需要的数据是否在页缓存中,在则放弃访问磁盘,直接从内存中读取,这个行为称作缓存命中;若没有命中,则调度块IO操作从磁盘中读取数据。缓存可以持有一个文件的全部内容,也可以存储文件的部分页。
写缓存
当内核开始写操作时,缓存实现为三种策略:
- 不缓存,高速缓存不缓存任何写操作,当写时直接跳过缓存,写到磁盘,使缓存中的数据失效,下次读时重新从磁盘中读取数据。这个策略不缓存写操作,而且需要额外操作使缓存数据失效。
- 写操作自动更新内存缓存,同时更新磁盘文件。写操作直接穿透缓存到磁盘中,这种策略不需要让缓存失效,缓存数据时刻与磁盘存储保持一致。
- 回写策略,Linux采用了这种策略,也就是写操作直接写入缓存中,但是磁盘中对应的文件不会立即更新,而是将缓存标记为脏的数据,并加入到脏页链表中。然后由回写进程周期性的将链表中的脏页回写到磁盘,使磁盘中的数据与内存中的数据保持一致。最后清理脏页标识,脏指的是缓存中的数据未与磁盘数据同步。回写策略认为好与写穿透策略,因为延迟写方便在以后的时间内合并更多的数据和再一次刷新。
缓存回收
Linux内核的缓存回收是通过选择干净页进行简单替换,如果缓存中没有足够的干净页,则强制进行回写操作,腾出更多的干净页面。回收算法:
- LRU,最近最少使用,LRU算法通过跟踪每个页面的访问轨迹,回收最老时间戳的页面。数据如果越久没有被访问,则不太可能最近再被访问。对于许多只被访问一次的,而不再进行下一次访问的场景,LRU表现不佳,因为但内核并不知道一个文件只被访问一次,它只知道过去访问了多少次,将这些页面放到LRU链的顶端不是最优解。
- 双链策略,一个修改过的LRU,维护连个链表,活跃链表和非活跃链表。活跃链表是热的,不会被换出;非活跃链表则可以被换出。两个链表都被伪LRU规则维护:页面从尾部加入,从头部移除。如果活跃链表页面过多,则头部页面被重新移回非活跃链表,以便被回收。在活跃链表中的页面必须在其被访问时就处于非活跃链表中。
address_space
页高速缓存缓存的是内存页面,缓存来自对正规文件、块设备文件、内存映射文件的读写。页高速缓存包含了最近被访问过的文件的数据块。Linux内核对被缓存的页面定义非常宽泛,可以缓存任何基于页的对象,包括各种类型的文件和各种类型的内存映射,要不然在普通文件inode里面就可以直接管理页缓存。
所以Linux内核使用address_space结构体管理缓存项和页IO操作,每个缓存文件只和一个address_space相关联。该结构包含文件对应的所有页,嵌入在拥有该页面的inode对象中。其中,address_space_operations是对应address_apce结构体的操作结构体,主要包括:
1 | writepage: 写操作,将页写到所有者所在的磁盘; |
其中最重要的方法是readpage/readpages、writepage/writepages、prepare_write和commit_write(最新版本已不存在)。在大多数情况下,这些方法把所有者的inode对象和访问物理设备的底层设备驱动联系起来。如,为普通文件的inode实现readpage方法的函数知道如何确定文件页的对应块在物理磁盘上的位置。
一个页面缓存的读操作如下:
- Linux内核试图在页高速缓存中找到需要的数据。调用page = find_get_page(mapping, index),index是文件中以页面为单位的位置。
- 如果没有在高速缓存中,find_get_page返回一个NULL,并且内核分配一个新页面,将之前的页加入页高速缓存中。
- 从页高速缓存中数据,然后返回给用户。
对于写操作,当页被修改了,仅需调用SetPageDirty将page设置为脏,内核会在晚些时候通过writepage()将页写出。
任何IO操作前,内核都需要检查页是否已经在页高速缓存中,如果这种检查不够高效和迅速,搜索和检查页高速缓存带来的开销,会抵消使用页高速缓存所带来的好处,目前Linux内核使用xarray保存所有缓存的页,只需要给定文件address_space和对应页面的index,就可以从xarray中快速查找到所需要的页。
回写线程
flush线程负责脏页回写磁盘。
读写文件流程
借助分析读写一个文件的流程,加深对I/O系统的理解。
推荐阅读陈义全大佬的Linux内核读文件过程。